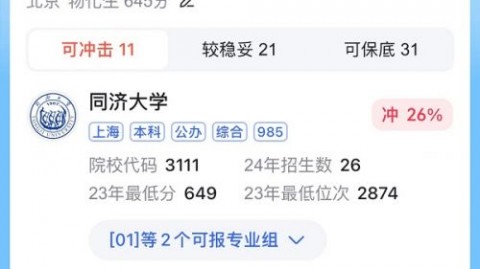
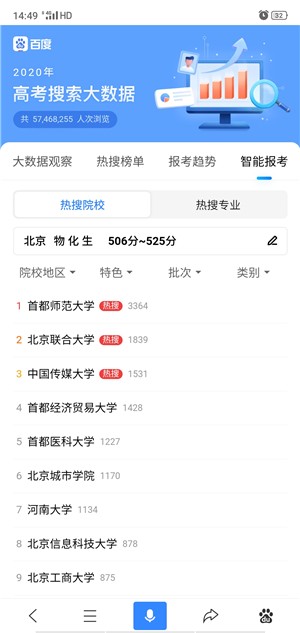
2026年高考已进入倒计时。当千万考生与家长被3000多所高校、792个本科专业以及“院校专业组”等复杂规则压得喘不过气时,AI志愿助手机正以前所未有的速度重塑升学规划领域-10。它将大数据分析与人工智能推荐算法深度融合,从“翻书查数据、凭经验报志愿”的传统模式,升级为“数据决策+智能匹配”的科学填报体系。很多人对AI志愿推荐的理解仍停留在“它会根据分数推荐学校”的浅层认知上,对于背后的推荐算法如何运作、协同过滤与深度学习如何协同、底层依赖哪些核心技术等问题,往往一知半解。本文将从痛点切入,系统讲解AI志愿推荐的核心概念、算法原理、代码实现与底层技术,助你建立从理论到实战的完整知识链路。
一、痛点切入:传统志愿填报的困境

在AI介入之前,志愿填报主要依赖两种方式:一是手动翻阅招生指南和历年录取数据,凭借经验判断“这个分数能上什么学校”;二是使用志愿卡类查询工具,输入分数后返回一个基于线差匹配的院校列表。
以下是一个传统查询方式的简化实现:
def traditional_match(score, year, province): 从历年录取数据中筛选分数线在score附近的院校 candidates = [] for school in admission_data: line_diff = school['admission_line'] - score if abs(line_diff) <= 20: candidates.append({ 'name': school['name'], 'admission_line': school['admission_line'], 'difference': line_diff }) return sorted(candidates, key=lambda x: abs(x['difference']))
传统模式的核心缺陷十分明显:
耦合高、扩展性差:算法仅依赖“往年录取线差”这一维度的数据,无法融入专业兴趣、地域偏好、学科评估等级、就业前景等多维因素-19。
个性化严重缺失:向“物理特长”的考生推荐文科专业、给“想留在本省”的学生推送外地院校的情况屡见不鲜-19。
决策效率低下:10天填报期内要消化上百所院校的海量信息,考生和家长陷入“信息过载”的困境-19。
正是这些传统模式的天然短板,催生了以AI志愿助手机为代表的新一代智能推荐系统。它不再只是“分数对学校”的简单匹配,而是将考生画像与多维数据进行深度融合,生成真正个性化的志愿填报方案-6。
二、核心概念讲解:推荐系统(Recommender System)
标准定义:推荐系统(Recommender System,RS)是一种信息过滤系统,旨在通过分析用户的历史行为、偏好和上下文信息,预测用户对未知物品的感兴趣程度,并主动推送最相关的物品。
生活化类比:想象你去一家新开的餐厅,服务员并不认识你。她先问:“您喜欢辣还是不辣?之前喜欢吃川菜还是粤菜?”——这是基于内容的推荐,根据你提供的偏好来匹配。接着,她又补充:“和您口味相近的其他顾客,最近都点了新推出的酸菜鱼”——这是协同过滤推荐,借助相似用户的选择来补充你的未知偏好。
在AI志愿助手机中的应用价值:推荐系统将考生的分数位次、专业兴趣、地域倾向等作为输入,将全国高校和专业作为“物品库”,通过多维匹配算法输出“冲、稳、保”梯度的志愿方案,从而解决传统填报中信息不对称和决策困难的核心痛点-19。
三、关联概念讲解:协同过滤算法(Collaborative Filtering)
标准定义:协同过滤(Collaborative Filtering,CF)是推荐系统中最经典、应用最广泛的算法之一。其核心思想是“物以类聚、人以群分”——利用用户-物品交互矩阵中的相似性进行外推-33。
协同过滤主要有两种经典实现形式:
基于用户的协同过滤(UserCF) :寻找与目标考生兴趣相似的其他考生群体(即“邻居用户”),将他们选择过的院校和专业推荐给目标考生-12。
基于物品的协同过滤(ItemCF) :找出与目标考生喜欢过的院校/专业相似的候选院校/专业进行推荐-33。
在AI志愿助手机中的运行机制:系统通过分析大量考生的择校行为数据,发现考生A和考生B在分数区间、选科组合、地域偏好上高度相似。当考生A查询志愿建议时,系统会参考考生B选择的学校,将考生B选择但考生A尚未关注的院校推荐给A-12。这弥补了单纯依靠“内容匹配”无法发现隐性偏好的不足。
与推荐系统的关系:推荐系统是一个宏观概念,而协同过滤是实现个性化推荐的一种具体算法手段。推荐系统可以同时使用协同过滤、基于内容的推荐、深度学习推荐等多种算法,协同过滤专注于利用群体智慧来发现用户偏好。
四、概念关系与区别总结
| 维度 | 推荐系统 | 协同过滤算法 |
|---|---|---|
| 本质 | 系统/框架 | 算法/手段 |
| 定位 | 整体解决方案 | 局部实现技术 |
| 数据来源 | 用户画像、物品特征、交互行为 | 仅依赖用户-物品交互矩阵 |
| 在AI志愿助手机中的角色 | 全流程框架 | 核心匹配引擎之一 |
一句话记忆:推荐系统是“大脑”,负责统筹全局的推荐策略;协同过滤是“神经系统”中的一条关键通路,负责传递“相似的人喜欢相似的东西”这一群体智慧信号。
五、代码示例:基于ItemCF的院校推荐极简实现
以下是一个简化的基于物品的协同过滤推荐核心代码,用于AI志愿助手机中为考生推荐相似院校:
import numpy as np from collections import defaultdict def item_based_cf_recommend(user_history, user_item_matrix, top_k=5): """ 基于物品的协同过滤推荐实现 :param user_history: 考生已选中的院校列表 :param user_item_matrix: 用户-院校交互矩阵(二维数组,行=考生,列=院校) :param top_k: 推荐数量 :return: 推荐院校列表及其相似度得分 """ 步骤1:构建物品-用户倒排索引 item_users = defaultdict(set) for user_id, items in enumerate(user_item_matrix): for item_id in items: item_users[item_id].add(user_id) 步骤2:计算院校之间的余弦相似度 items = list(item_users.keys()) n_items = len(items) item_similarity = {} for i in range(n_items): for j in range(i + 1, n_items): common_users = item_users[items[i]] & item_users[items[j]] if len(common_users) > 0: 余弦相似度公式 sim = len(common_users) / np.sqrt( len(item_users[items[i]]) len(item_users[items[j]]) ) item_similarity[(items[i], items[j])] = sim item_similarity[(items[j], items[i])] = sim 步骤3:基于考生历史记录生成推荐 scores = defaultdict(float) for item in user_history: for candidate, sim in item_similarity.items(): if candidate[0] == item and candidate[1] not in user_history: scores[candidate[1]] += sim elif candidate[1] == item and candidate[0] not in user_history: scores[candidate[0]] += sim 步骤4:排序返回Top-K推荐 return sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
执行流程说明:该算法首先构建院校-用户的倒排索引,记录每一所院校被哪些考生选择过;然后计算任意两所院校之间的余弦相似度,相似度越高说明被同一类考生选择的概率越大;最后根据目标考生已选择的院校,推荐与之相似度最高的其他院校。
六、底层原理与技术支撑
AI志愿助手机中的推荐能力并非凭空产生,其背后依赖一系列核心技术栈:
1. 大规模数据处理:系统接入全国2800+高校的招生数据、教育部高校数据库、历年录取分数线等多源数据,使用Hadoop集群和Spark MLlib进行海量数据的存储与处理-12-19。
2. 机器学习算法库:协同过滤、矩阵分解等推荐算法的实现,在工业场景中通常依赖Scikit-learn、TensorFlow或PyTorch等框架。例如,使用Scikit-learn可以快速实现分数位次预测和录取概率计算-23。
3. 大模型推理能力:在传统协同过滤之外,先进的AI志愿助手机已开始集成大语言模型(LLM),如依托DeepSeek大模型,结合学生的成绩、专业偏好与地域倾向,智能生成更具前瞻性的志愿填报方案-10。大模型负责处理自然语言交互、政策文本理解等复杂推理任务。
4. 规则引擎:新高考选科限制、“专业+院校”绑定等动态约束条件,需要通过PySpark等规则引擎进行处理,确保推荐结果符合招生政策要求-23。
这些底层技术共同构成AI志愿助手机的“发动机”,上层推荐算法的每一次计算都依赖它们的有力支撑。
七、高频面试题与参考答案
面试题1:协同过滤有哪些优缺点?在志愿推荐场景中如何应对其不足?
参考答案要点:
优点:简单有效、可解释性较强,能够挖掘用户潜在兴趣,无需领域知识-33。
缺点:存在冷启动问题(新用户/新物品无历史数据)、数据稀疏性问题(用户-物品矩阵中大多数元素为空)、易受噪声影响。
志愿场景应对策略:冷启动期可结合基于内容的推荐(依据分数位次进行初步匹配)做混合推荐;数据稀疏问题可通过矩阵分解降维来缓解-28-33。
面试题2:ItemCF和UserCF分别适用于什么场景?志愿填报系统应优先选择哪一种?
参考答案要点:
UserCF适用于用户数较少、物品更新频繁的场景(如新闻推荐)。
ItemCF适用于物品数相对稳定、用户个性化需求强的场景(如电商推荐)。
在AI志愿助手机中,院校和专业的数量相对稳定,且每位考生的偏好差异显著,ItemCF更为适用——它基于考生已关注的院校/专业来推荐相似院校,推荐结果更聚焦、可解释性更强-。
面试题3:如何设计一个支持大模型的AI志愿推荐系统?
参考答案要点:
分层架构:召回层使用协同过滤+向量检索从全量院校库中筛选候选集(几百所);精排层使用大模型(如DeepSeek)结合分数、兴趣、地域等多维特征进行精细化排序-10。
混合策略:传统算法处理结构化数据匹配(分数、位次),大模型处理非结构化推理(政策解读、对话问答)。
可扩展性考虑:当大模型服务不可用时,需设计降级策略,自动切换回传统推荐算法保证服务可用性。
八、结尾总结
核心知识回顾:本文系统梳理了AI志愿助手机推荐系统的三大关键知识点——
推荐系统 vs 协同过滤:推荐系统是宏观框架,协同过滤是实现该框架的核心算法手段。
ItemCF原理:基于院校之间的相似度进行推荐,计算余弦相似度→生成候选→排序输出。
底层技术栈:大数据处理(Hadoop/Spark)+机器学习框架(Scikit-learn/TensorFlow)+大模型推理(DeepSeek等)。
重点与易错提醒:切莫将“推荐系统”与“协同过滤”混为一谈——前者是整体方案,后者是具体算法。在设计志愿推荐系统时,要根据数据特点合理选择UserCF还是ItemCF,并根据业务需求设计传统算法与大模型的协同策略。
下一篇预告:下一期我们将深入探讨AI志愿助手机中的冷启动问题与混合推荐策略,从“无历史数据时如何给新考生做推荐”入手,讲解基于内容的推荐、知识图谱推荐等进阶技术,敬请期待!